【TDengine 使用环境】
【TDengine 版本】
3.3.7.5-开源版
【操作系统以及版本】
centos 7.6
【部署方式】容器/非容器部署
k8s 官方 helm 部署
k8s版本:v1.23.17
【集群节点数】
3
【集群副本数】
3
【描述业务影响】
【问题复现路径/shan】做过哪些操作出现的问题
部署了3台节点,3台dnode都作为mnode
此时有1台leader,2台follower
对其中一台follower执行delete pod操作
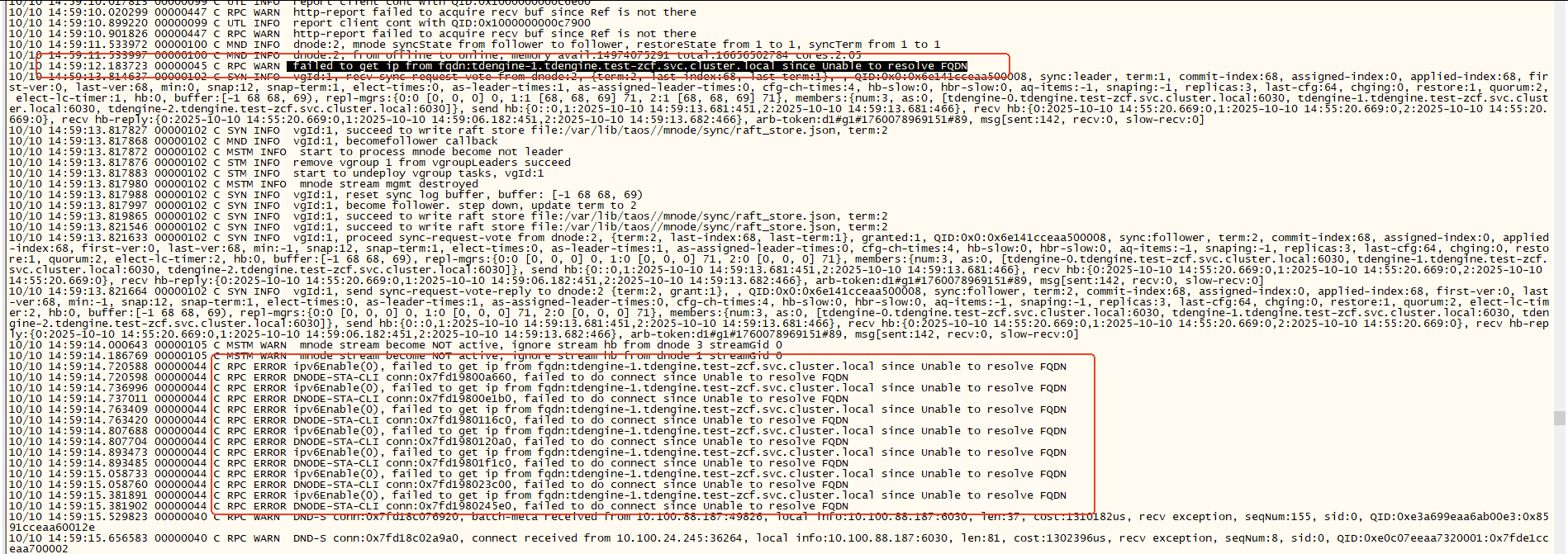
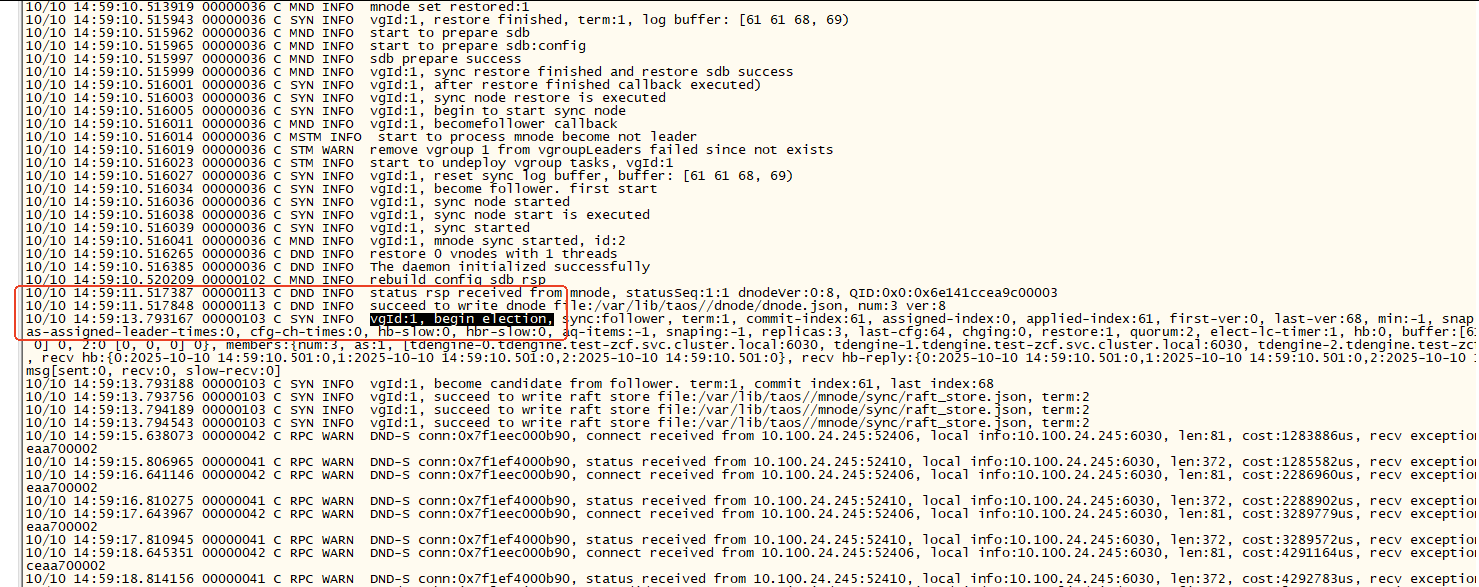
被delete的节点重新加入集群,但是此时leader节点会报错: failed to get ip from fqdn tdengine-0.test-zcf.svc.cluster.local since unable to resolve fqdn,大概会持续5s,可能是因为k8s重新恢复pod导致的ip切换?
此时由于重新加入集群的节点在3s内没有建立与mnode的通信(不知道我理解的对不对),所以重新发起选举;
这样就会导致整个集群会重新进行raft选举,持续时间10-60s不等,这段时间内集群无法正常进行访问。
【遇到的问题:问题现象及影响】
目前mnode从节点挂掉也会导致整个集群重新进行选举,访问不可达希望单个节点宕机不影响3个节点集群的稳定性】
【资源配置】
【报错完整截图】
重新加入的follower节点
你分析的没错,3秒内没有给重新加入的follower发送心跳,所以重新加入的节点会发起选举。所以这个问题还是要看,怎么解决leader解析fqdn报错问题,怎么正常发心跳给重新加入的follower。
我目前是认为 leader 访问 follower 是不是访问的是还未更新的ep 地址,然后新的pod拉起来后 fqdn对应的ip地址发生了改变,所以会有短暂的无法请求到,而新起的pod则是可以正常访问到leader。
不过还是需要打出debug日志再验证下,还没理解到位应该是。@TDuser_WR4d_8328
tdengine里使用的ep,并且会把ep(也就是fqdn)解析成ip。解析不出ip,不是tdengine控制的。这个ep的是否更新,是系统控制的,tdengine也控制不了。
目前我们使用hostNetwork的配置将每个pod分配到不同的服务器节点才能解决问题,
但感觉这对k8s的部署运维是不友好的,是不是我的每次扩容一台节点都需要一台服务器@TDuser_WR4d_8328
这个问题解决了吗, 我也遇到类似问题 ,请问怎么解决的
Roy
2025 年12 月 10 日 09:16
12
这个主要是 K8S 的问题,如果需要技术协助的话可以单独联系。
解决了吗?兄弟,我们也碰到了类似的问题,除了使用hostnetwork模式
system
2026 年1 月 22 日 08:04
15
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。