【TDengine 使用环境】
测试
【TDengine 版本】
3.3.7.0
【操作系统以及版本】
centos7
【部署方式】容器/非容器部署
容器
【集群节点数】
1
【集群副本数】
1
【描述业务影响】
【问题复现路径/shan】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
数据库突然崩溃,无法访问。
【资源配置】
【报错完整截图】(不要大段的粘贴报错代码,论坛直接看报错代码不直观)
错误日志如下
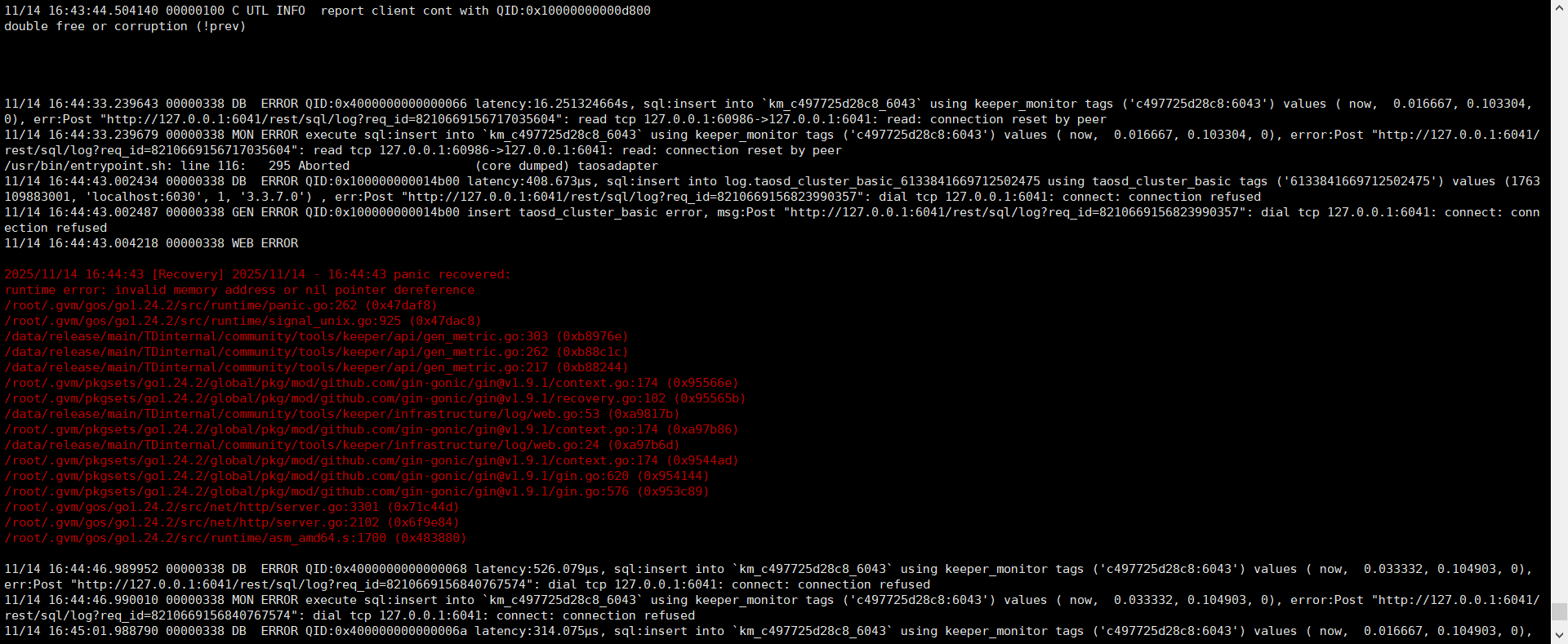
double free or corruption (!prev)
11/14 16:44:33.239643 00000338 DB ERROR QID:0x4000000000000066 latency:16.251324664s, sql:insert into km_c497725d28c8_6043 using keeper_monitor tags (‘c497725d28c8:6043’) values ( now, 0.016667, 0.103304, 0), err:Post “http://127.0.0.1:6041/rest/sql/log?req_id=8210669156717035604”: read tcp 127.0.0.1:60986->127.0.0.1:6041: read: connection reset by peer11/14 16:44:33.239679 00000338 MON ERROR execute sql:insert into km_c497725d28c8_6043 using keeper_monitor tags (‘c497725d28c8:6043’) values ( now, 0.016667, 0.103304, 0), error:Post “http://127.0.0.1:6041/rest/sql/log?req_id=8210669156717035604”: read tcp 127.0.0.1:60986->127.0.0.1:6041: read: connection reset by peer/usr/bin/entrypoint.sh: line 116: 295 Aborted (core dumped) taosadapter11/14 16:44:43.002434 00000338 DB ERROR QID:0x100000000014b00 latency:408.673?s, sql:insert into log.taosd_cluster_basic_6133841669712502475 using taosd_cluster_basic tags (‘6133841669712502475’) values (1763109883001, ‘localhost:6030’, 1, ‘3.3.7.0’) , err:Post “http://127.0.0.1:6041/rest/sql/log?req_id=8210669156823990357”: dial tcp 127.0.0.1:6041: connect: connection refused11/14 16:44:43.002487 00000338 GEN ERROR QID:0x100000000014b00 insert taosd_cluster_basic error, msg:Post “http://127.0.0.1:6041/rest/sql/log?req_id=8210669156823990357”: dial tcp 127.0.0.1:6041: connect: connection refused11/14 16:44:43.004218 00000338 WEB ERROR
2025/11/14 16:44:43 [Recovery] 2025/11/14 - 16:44:43 panic recovered:runtime error: invalid memory address or nil pointer dereference/root/.gvm/gos/go1.24.2/src/runtime/panic.go:262 (0x47daf8)/root/.gvm/gos/go1.24.2/src/runtime/signal_unix.go:925 (0x47dac8)/data/release/main/TDinternal/community/tools/keeper/api/gen_metric.go:303 (0xb8976e)/data/release/main/TDinternal/community/tools/keeper/api/gen_metric.go:262 (0xb88c1c)/data/release/main/TDinternal/community/tools/keeper/api/gen_metric.go:217 (0xb88244)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/context.go:174 (0x95566e)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/recovery.go:102 (0x95565b)/data/release/main/TDinternal/community/tools/keeper/infrastructure/log/web.go:53 (0xa9817b)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/context.go:174 (0xa97b86)/data/release/main/TDinternal/community/tools/keeper/infrastructure/log/web.go:24 (0xa97b6d)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/context.go:174 (0x9544ad)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/gin.go:620 (0x954144)/root/.gvm/pkgsets/go1.24.2/global/pkg/mod/github.com/gin-gonic/gin@v1.9.1/gin.go:576 (0x953c89)/root/.gvm/gos/go1.24.2/src/net/http/server.go:3301 (0x71c44d)/root/.gvm/gos/go1.24.2/src/net/http/server.go:2102 (0x6f9e84)/root/.gvm/gos/go1.24.2/src/runtime/asm_amd64.s:1700 (0x483880)